Дайджест новостей: события из мира науки

Системы обнаружения вторжений
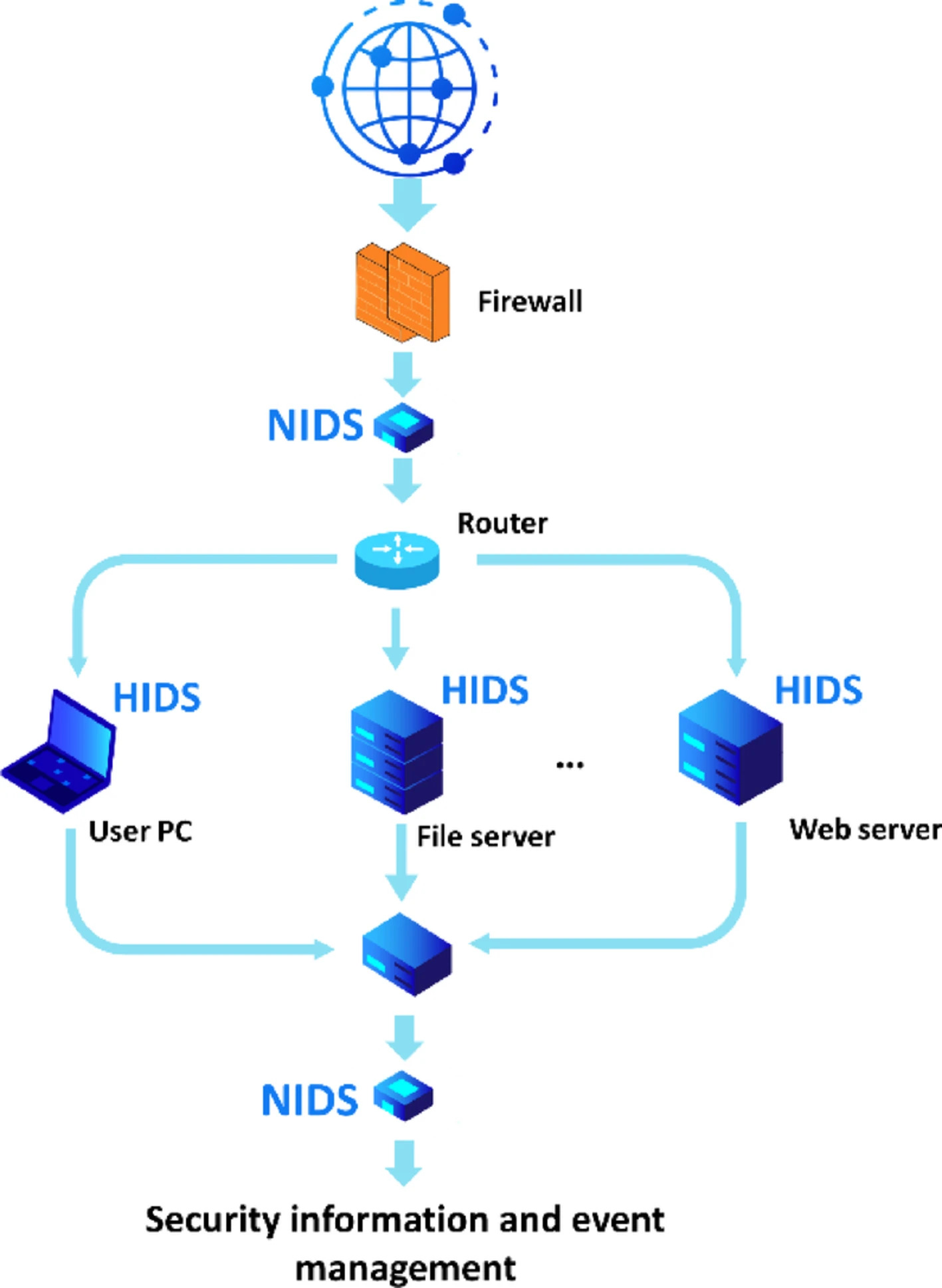 5 ноября была опубликована статья «A comprehensive survey on intrusion detection systems with advances in machine learning, deep learning and emerging cybersecurity challenges», в которой авторы предлагают систематический обзор современных систем обнаружения вторжений (IDS) с упором на методы машинного обучения (ML) и глубокого обучения (DL). Рассматриваются два основных типа IDS – сетевые (NIDS) и хост-основанные (HIDS). В техническом плане описано, как входные данные сетевого трафика преобразуются в вектор признаков: количество пакетов, длительность соединения и др. Затем применяются методы для отбора этих признаков и преобразования, например, PCA перед подачей в классификатор. Среди моделей упомянуты SVM, случайный лес, градиентный бустинг, а также глубокие сети: AE, LSTM. Авторы указывают, что важными метриками являются Accuracy, Detection Rate и False Positive Rate. В качестве пути развития предлагается создание гибридных систем, сочетающих ML и DL с классическими эвристиками, активное обучение (active learning) и онлайн-адаптацию моделей, а также усиление взаимодействия инженеров безопасности и специалистов по данным.
5 ноября была опубликована статья «A comprehensive survey on intrusion detection systems with advances in machine learning, deep learning and emerging cybersecurity challenges», в которой авторы предлагают систематический обзор современных систем обнаружения вторжений (IDS) с упором на методы машинного обучения (ML) и глубокого обучения (DL). Рассматриваются два основных типа IDS – сетевые (NIDS) и хост-основанные (HIDS). В техническом плане описано, как входные данные сетевого трафика преобразуются в вектор признаков: количество пакетов, длительность соединения и др. Затем применяются методы для отбора этих признаков и преобразования, например, PCA перед подачей в классификатор. Среди моделей упомянуты SVM, случайный лес, градиентный бустинг, а также глубокие сети: AE, LSTM. Авторы указывают, что важными метриками являются Accuracy, Detection Rate и False Positive Rate. В качестве пути развития предлагается создание гибридных систем, сочетающих ML и DL с классическими эвристиками, активное обучение (active learning) и онлайн-адаптацию моделей, а также усиление взаимодействия инженеров безопасности и специалистов по данным.
Модификация машин Тьюринга
 Статья «Modifying Turing Machines for General Intelligence» предлагает новую перспективу на архитектуру вычислительных систем, способных к общему интеллекту (AGI). Исходя из классической модели машины Тьюринга, авторы вводят концепцию «машины Тьюринга с метакогнитивной памятью»: устройство, которое не только выполняет алгоритмы, но и способно «осознавать» и адаптировать свои собственные вычисления, добавляя слои памяти и метаопераций. Технически, основная часть – это классическая машина Тьюринга с лентой, головкой и таблицей переходов, но дополненная модулем «Meta-Memory», который хранит правила и мета-правила обработки. Этот модуль позволяет системе периодически анализировать прошлые вычисления, выявлять шаблоны и генерировать изменения в таблице переходов. Например, машина Тьюринга делает шаги: прочитать символ, на основе состояния и символа записать новый символ, переместить головку, изменить состояние. В новой модели добавляется иной функционал: каждые N шагов машина обращается к модулю Meta-Memory и проверяет, выполнялась ли серия шагов неэффективно, имело ли место большое количество переходов без прогресса. Если факт неэффективности подтверждается, модуль генерирует новую таблицу переходов или модифицирует текущую и сохраняет её, как вспомогательный алгоритм.
Статья «Modifying Turing Machines for General Intelligence» предлагает новую перспективу на архитектуру вычислительных систем, способных к общему интеллекту (AGI). Исходя из классической модели машины Тьюринга, авторы вводят концепцию «машины Тьюринга с метакогнитивной памятью»: устройство, которое не только выполняет алгоритмы, но и способно «осознавать» и адаптировать свои собственные вычисления, добавляя слои памяти и метаопераций. Технически, основная часть – это классическая машина Тьюринга с лентой, головкой и таблицей переходов, но дополненная модулем «Meta-Memory», который хранит правила и мета-правила обработки. Этот модуль позволяет системе периодически анализировать прошлые вычисления, выявлять шаблоны и генерировать изменения в таблице переходов. Например, машина Тьюринга делает шаги: прочитать символ, на основе состояния и символа записать новый символ, переместить головку, изменить состояние. В новой модели добавляется иной функционал: каждые N шагов машина обращается к модулю Meta-Memory и проверяет, выполнялась ли серия шагов неэффективно, имело ли место большое количество переходов без прогресса. Если факт неэффективности подтверждается, модуль генерирует новую таблицу переходов или модифицирует текущую и сохраняет её, как вспомогательный алгоритм.
Укрощение асинхронности в распределенных платежных системах: гарантии, идемпотентность и сквозное согласование
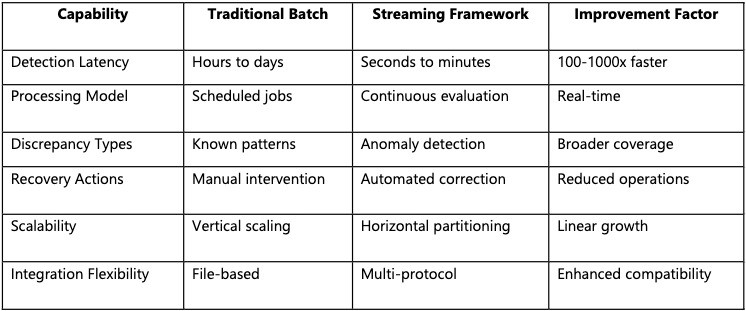 Одноименная статья анализирует проблему, которая заключается в том, что в распределённых платёжных системах операции транзакции могут выполняться асинхронно, и чтобы система работала корректно, необходимы гарантии идемпотентности и сквозное согласование состояния между компонентами. При приёме операции создаётся уникальный идентификатор транзакции (TxID). Принимающие сервисы фиксируют журнал с TxID и состоянием, например, «PENDING → COMMITTED». Если система обнаруживает, что TxID уже обработан – повторный эффект отсутствует. Если сеть ломается до COMMITTED, запускается компенсационная операция, например, ReverseTx и вся цепочка сервисов получает уведомление через очередь сообщений (с помощью инструментов Kafka/RabbitMQ). Затем выполняется «reconciliation»: сверка состояний сервисов, и если один сервис завис – инициируется восстановление.
Одноименная статья анализирует проблему, которая заключается в том, что в распределённых платёжных системах операции транзакции могут выполняться асинхронно, и чтобы система работала корректно, необходимы гарантии идемпотентности и сквозное согласование состояния между компонентами. При приёме операции создаётся уникальный идентификатор транзакции (TxID). Принимающие сервисы фиксируют журнал с TxID и состоянием, например, «PENDING → COMMITTED». Если система обнаруживает, что TxID уже обработан – повторный эффект отсутствует. Если сеть ломается до COMMITTED, запускается компенсационная операция, например, ReverseTx и вся цепочка сервисов получает уведомление через очередь сообщений (с помощью инструментов Kafka/RabbitMQ). Затем выполняется «reconciliation»: сверка состояний сервисов, и если один сервис завис – инициируется восстановление.
Авторы предлагают следующий алгоритм:
Такая схема позволяет обеспечить конечную консистентность (eventual consistency) и гарантии, что результат операции будет либо применён, либо компенсирован, и состояние сервисов — синхронизировано.
Вложенное обучение
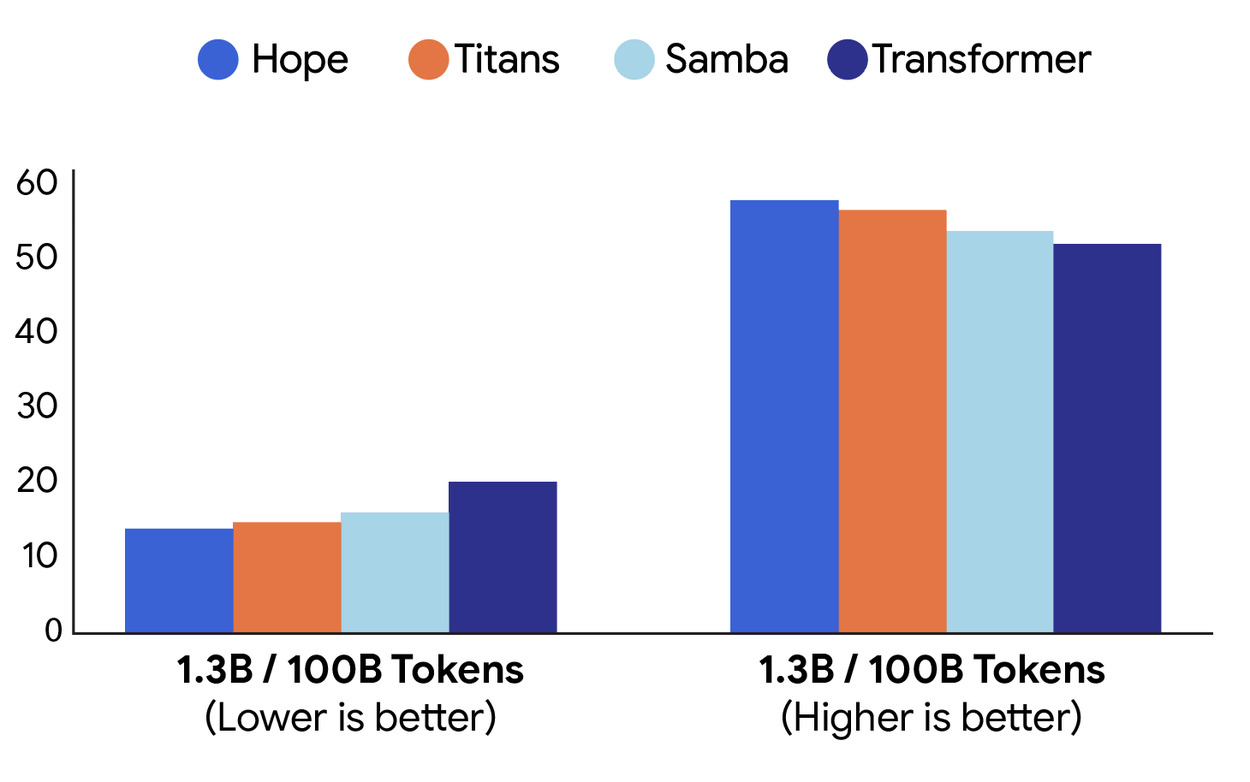 Google предложили решение проблемы, которой страдают все современные LLM-модели. «Катастрофическое забывание» – фундаментальная проблема, связанная с непрерывным обучением. Данное состояние возникает, когда при непрерывном обучении, изучение новых задач приводит к потере навыков решений старых. В статье «Nested Learning: The illusion of Deep Learning Architectures» представляют вложенное обучение, которое устраняет этот пробел. Подход рассматривает одну модель ML не как один непрерывный процесс, а как систему взаимосвязанных многоуровневых задач обучения, каждая из которых имеет свой поток контекста и свой ритм обновления параметра. На верхнем уровне медленные компоненты аккумулируют устойчивые знания, которые не меняются годами. На нижних – небольшие компоненты, которые можно переобучить сравнительно быстро. В качестве подтверждения Google использовали принципы Nested Learning для разработки Hope, варианта архитектуры Titans (представляют собой модули долговременной памяти, которые приоритизируют воспоминания в зависимости от их неожиданности). Результаты эксперимента подтвердили преимущество вложенного обучения. На разнообразном наборе задач моделирования, на общепринятых и общедоступных языках рассуждений и на основе здравого смысла архитектура Hope демонстрирует меньшую путаницу и более высокую точность по сравнению с современными рекуррентными моделями и стандартными преобразователями.
Google предложили решение проблемы, которой страдают все современные LLM-модели. «Катастрофическое забывание» – фундаментальная проблема, связанная с непрерывным обучением. Данное состояние возникает, когда при непрерывном обучении, изучение новых задач приводит к потере навыков решений старых. В статье «Nested Learning: The illusion of Deep Learning Architectures» представляют вложенное обучение, которое устраняет этот пробел. Подход рассматривает одну модель ML не как один непрерывный процесс, а как систему взаимосвязанных многоуровневых задач обучения, каждая из которых имеет свой поток контекста и свой ритм обновления параметра. На верхнем уровне медленные компоненты аккумулируют устойчивые знания, которые не меняются годами. На нижних – небольшие компоненты, которые можно переобучить сравнительно быстро. В качестве подтверждения Google использовали принципы Nested Learning для разработки Hope, варианта архитектуры Titans (представляют собой модули долговременной памяти, которые приоритизируют воспоминания в зависимости от их неожиданности). Результаты эксперимента подтвердили преимущество вложенного обучения. На разнообразном наборе задач моделирования, на общепринятых и общедоступных языках рассуждений и на основе здравого смысла архитектура Hope демонстрирует меньшую путаницу и более высокую точность по сравнению с современными рекуррентными моделями и стандартными преобразователями.
ТОП-5 ИБ-событий недели
 Центр мониторинга и реагирования на инциденты информационной безопасности CSIRT опубликовали критические уязвимости. Делимся с вами с тремя наиболее важными.
Центр мониторинга и реагирования на инциденты информационной безопасности CSIRT опубликовали критические уязвимости. Делимся с вами с тремя наиболее важными.
SQLite 3.51
 Состоялся релиз легковесной СУБД. Привели ниже основные изменения и доработки.
Состоялся релиз легковесной СУБД. Привели ниже основные изменения и доработки.