В популярном во всем мире научном интернет-издании INSIDE SCIENCE NEWS SERVICE опубликован материал “Massive Study Shows How Languages Change”, посвященный исследованию, выполненному в Лаборатории квантитативной лингвистики Института филологии и межкультурной коммуникации КФУ.
О многолетней работе лингвистов, проводивших компьютерный анализ больших массивов данных (около 500 миллиардов слов), и об изменении языка журналисту пресс-центра рассказал один из авторов статьи, профессор, главный научный сотрудник научно-образовательного центра по лингвистике им.И.А.Бодуэна де Куртенэ Института филологии и межкультурной коммуникации КФУ Валерий Соловьев.
- Валерий Дмитриевич, кто вошел в ваш творческий коллектив?
- Авторами напечатанной в британском Journal of The Royal Society Interface статьи “Universals versus historical contingencies in lexical evolution” стали ученые из нескольких стран и университетов. Иностранным автором исследования выступил Сорен Вихман, датчанин, работающий в Институте эволюционной антропологии общества Макса Планка в Германии. Россию представили два ученых Казанского университета - физик Владимир Бочкарев и я. Хочу отметить, что исследование проводилось в Казанской лингвистической лаборатории.
- Почему именно в Казанской лингвистической лаборатории? Чем обоснован этот выбор?
- В Казанском университете исследования на стыке лингвистики и компьютерных технологий начались почти полвека назад. Особенно интенсифицировались они после создания в 2005 году (совместно с Институтом языкознания РАН, Институтом русского языка РАН и Научно-исследовательским вычислительным центром МГУ) научно-образовательного центра по лингвистике им. И.А. Бодуэна де Куртенэ. Практически сразу же наш научно-образовательный центр стал победителем конкурса грантов Минобрнауки РФ среди НОЦ по лингвистике, а затем выиграл и еще два гранта министерства. В рамках этих проектов проводились исследования по компьютерной и квантитативной лингвистике. Так что у нас накоплен большой опыт в этой области.
- Легшее в основу статьи исследование посвящено изучению общих закономерностей эволюции лексики языков в последние два столетия. На какой массив данных вы опирались?
- Для исследования была выбрана Google Books Ngram Viewer.
- Насколько мне известно, в сумме во всех отсканированных книгах Google Books Ngram содержится более 500 миллиардов слов, в том числе, 50 миллиардов на русском языке. Не скрою, меня смутили числа, указанные в статье. Откуда взялось такое гигантское количество слов?
- Да, действительно, Google проделал гигантскую работу, переведя в цифровую форму 8 миллионов, то есть более 6%, всех изданных в мире книг между 1500 и 2008 годами (хотя они и столкнулись при этом с проблемой авторского права), - говорит Валерий Дмитриевич. - И этот корпус продолжает пополняться, а значит количество слов увеличиваться. К тому же в нашей работе разные словоформы оценивались, как разные слова.
- Видимо, это и стало причиной того, что авторы статьи, посчитали, что "выучить русский сложнее английского".
- Журналист в этой статье не совсем точно определил "сложность" русского языка по нашему исследованию. Русский язык совсем не прост для изучения: в нем сложные правила склонений, спряжений со всеми исключениями, множественные морфемы, позволяющие образовывать новые слова. Однако подтверждение "сложности" при изучении какого-либо языка мы совершенно не ставили ни целью, ни задачей нашего исследования.
- Как проводилось исследование?
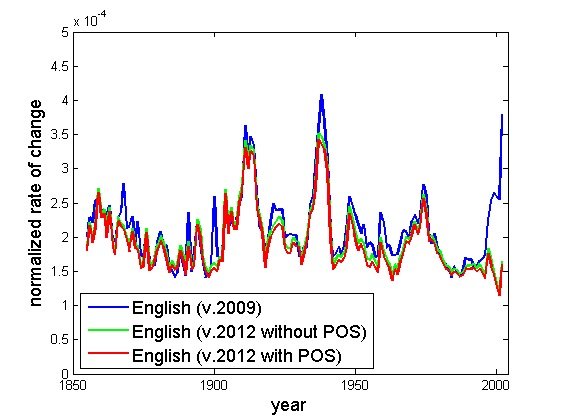
- Мы отталкивались от общего набора слов и словоформ, уделяя внимание данным за последние 180 лет. Серьезно осложняли исследование реформы орфографии, проведенные за это время в русском и немецком языках, поэтому полученные результаты следует принимать с определенными оговорками. Однако мы пришли к выводу об относительной стабильности скорости изменений лексики на больших промежутках времени.
- Анализировали только письменные языки?
- Конечно. В нашей статьи акцент сделан на шести основных европейских языках – английский, итальянский, немецкий, русский, французский, испанский.
- О чем говорят изменения словарного состава языка?
- Самое очевидное - изменения словарного состава говорят об изменении окружающего нас мира. Далее во многих случаях язык заимствует слово из другого языка, даже если обозначающее то же самое понятие слово в языке уже есть. Чаще всего (хотя и не всегда) заимствуемое слово короче уже существующего в языке. Это является проявлением стремления языка к экономии, к обеспечению возможности сказать больше за единицу времени. Простой пример - слово 'гей'. Соответствующее ему понятие в русском, согласно словарю Ушакова, - 'мужеложец'. Кто его будет сейчас употреблять? Особенно в сочетаниях, вроде 'гей-парад'.
Но есть и значительно более сложные ситуации. Например, слова 'стараться' и 'пытаться' за последние 200 лет практически не изменили свою семантику и по-прежнему остаются синонимами. Однако если 200 лет назад слово 'стараться' употреблялось в 100 раз чаще, чем 'пытаться', то в последние годы уже 'пытаться' употребляется несколько чаще. Это оказалось связано с глубокими перестройками когнитивных структур, которые не так-то просто объяснить. Специальная статья именно по этому вопросу выйдет в конце года в когнитивном сборнике в издательстве "Языки русской культуры" (Москва).
- А есть ли примеры, когда слово, которое раньше было специальным, может приобрести более широкое значение и заменить собой другое слово, имевшее ранее более широкий смысл?
- Раньше слово 'мусор' имело очень специальное значение. Согласно словарю Даля это: "остатки от каменной кладки и печной работы; мелкие остатки каменного угля". Для бытовых отходов употреблялось слово 'сор'.
Теперь 'мусор' относится к любым мелким отбросам и стало значительно более частотным, чем 'сор'.
Кроме подобного рода закономерностей общего характера, корпус Google Books Ngram позволяет обнаруживать интересные тенденции в развитии отдельных слов. Например, в последнее время слово divorce (развод) используется чаще, чем marry (брак, женитьба), а слово information (информация), чаще, чем wisdom (мудрость). Есть о чем задуматься.
- Что влияет на изменение словарного состава языка?
- На темпы языковых изменений влияют исторические события. Например, в викторианскую эпоху, характеризующуюся стабильностью, английский язык менялся медленно. Во время войн и социальных революций темпы языковой эволюции резко ускоряются.
- И какова средняя скорость изменения слов в языке?
- Отвечу на этот вопрос, напомнив, что такое глоттохронология. Это раздел исторической лингвистики, который позволяет определить возраст языков. Хорошо, если на каком-то языке сохранились древние и надежно датированные книги, по которым можно оценить и возраст языка. А если книг не сохранилось или язык вообще не имеет письменности, что тогда делать? Оказывается, сопоставляя число общих слов в родственных языках можно достаточно точно подсчитать, когда они разошлись от общего предка.
 И подсчитать это стало возможно, благодаря сделанному американским ученым Моррисом Сводешом наблюдению, что ядро языков меняется с постоянной скоростью. Тут уместно провести аналогию с радиоуглеродным методом датировка археологических находок, основанном на постоянстве скорости радиоактивного распада атомов. Эта идея как раз и привела Сводеша к открытию глоттохронологии.
И подсчитать это стало возможно, благодаря сделанному американским ученым Моррисом Сводешом наблюдению, что ядро языков меняется с постоянной скоростью. Тут уместно провести аналогию с радиоуглеродным методом датировка археологических находок, основанном на постоянстве скорости радиоактивного распада атомов. Эта идея как раз и привела Сводеша к открытию глоттохронологии.
Сводеш изучал ядро лексики - 100 или 200 наиболее стабильных слов. Он показал, что за 1000 лет в любом языке меняется приблизительно 14% слов ядра. Это, по сути, единственная на сегодняшний день надежно установленная количественными оценка скорости изменения слов.
- Какие у вас дальнейшие планы?
- В своем исследовании мы сделали только первый шаг. Надеемся, что к нам присоединятся наши коллеги и работа по анализу большой базы данных будет продолжена.